kube-rs 4개월 기여 기록

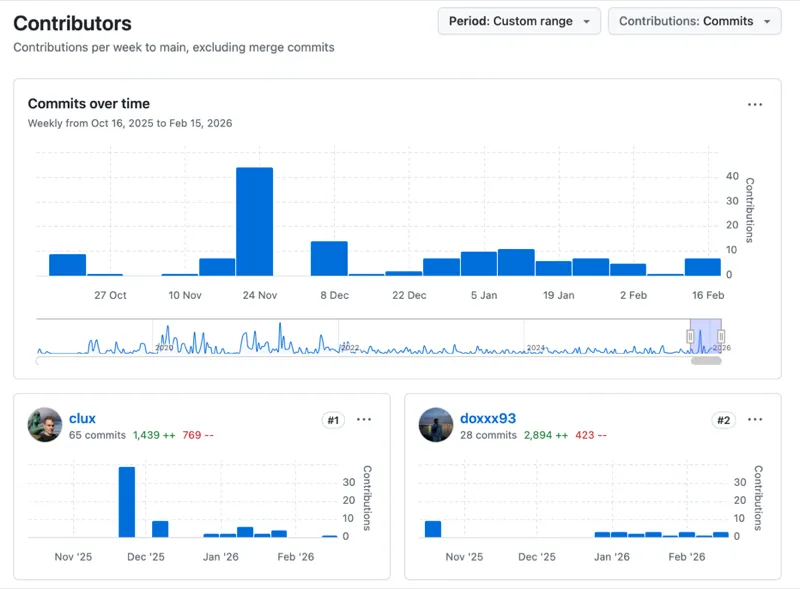
2025년 10월, GitHub에서 이슈 하나를 읽었다. 4개월 뒤 20개의 PR이 머지되었고, 프로젝트 멤버로 초대받았다.
그 사이에 있었던 일들을 기록해둔다.
시작
회사에서 kube-rs를 쓰고 있었다. Rust로 작성된 Kubernetes 클라이언트 라이브러리인데, 라이브러리를 충분히 활용하고 있다는 느낌이 아니었다. 회사 코드는 polling 구조로 되어 있었는데, watch로 바꾸면 더 효율적일 것 같았고, 그러면 reflector의 store도 활용할 수 있겠다는 생각이 들었다. 그래서 kube-rs를 제대로 알아보기로 했다.
reflector나 watch 쪽을 살펴보면서 해결이 안 된 이슈나 안정성 문제가 있는지 검토하다 보니 자연스럽게 이슈들을 보게 됐다.
작업 기록
첫 기여
이슈 #1830은 predicate 필터 버그였다. 리소스를 삭제하고 같은 이름으로 다시 만들면 컨트롤러가 새 리소스를 인식하지 못하는 문제로, 캐시가 이름만 보고 같은 리소스라고 판단해버리는 게 원인이었다. predicate 캐시의 HashMap을 보니 어떻게 하면 해결되겠다는 감이 왔다.
PR #1836을 올렸다. 파일 체인지가 1개라 부담이 없었다.
#1836 bug fix fix(predicate): track resource UID to handle recreated resources
- 배경: Kubernetes controller의 predicate 필터는 불필요한 reconciliation을 줄이는 핵심인데, 리소스 identity를 이름으로만 판단하고 있어서 재생성 시나리오를 커버하지 못하고 있었다
- 문제: 리소스 삭제 후 같은 이름으로 재생성하면, predicate 캐시가 이름만 비교해 동일 리소스로 판단. 컨트롤러가 새 리소스를 놓침
- 해결: 캐시 키에 UID를 포함하는
PredicateCacheKey도입
메인테이너 clux의 첫 리뷰:
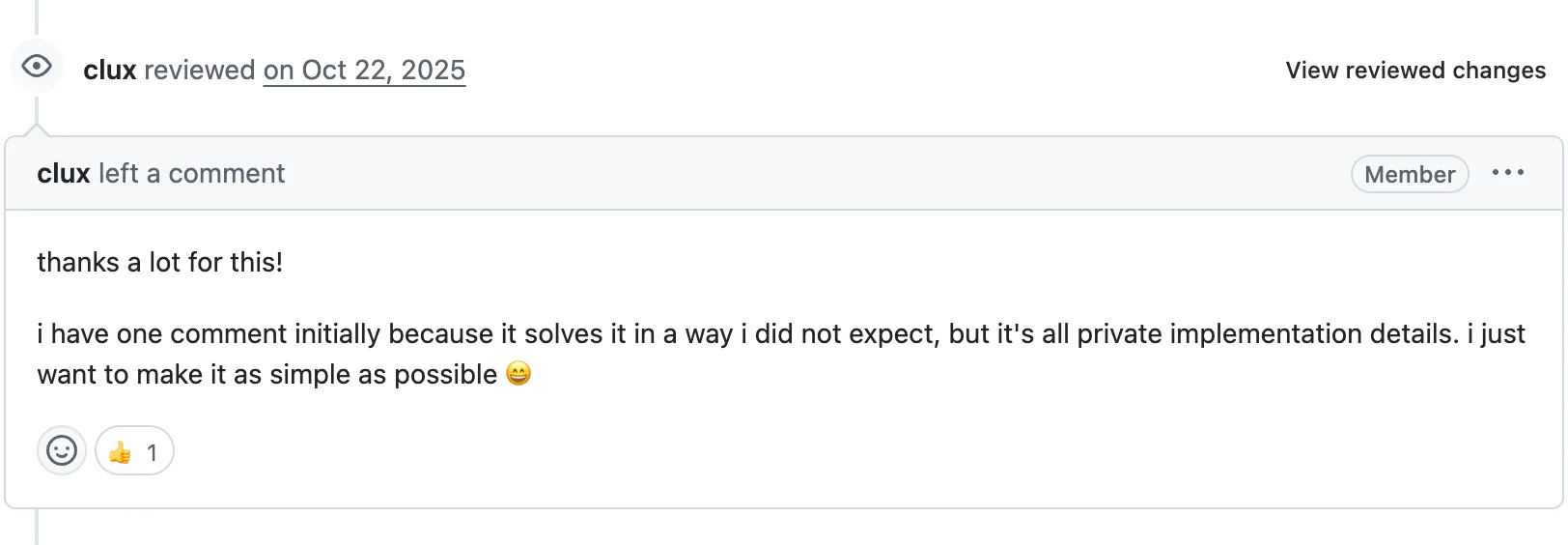

예상과 다른 방식으로 풀었는데, 어차피 내부 구현이니 최대한 단순하게 가고 싶다
전체적으로 좋다. 테스트에 하나 추가하면 좋겠고 코멘트 제안이 있는데, 사소한 것들이다. 깔끔하다
예상과 다른 방식이라고 했다. 제안한 방향으로 수정했더니 코드가 깔끔해졌다. 이 과정에서 lint를 두 번 연속 실패시키기도 했지만, 덕분에 justfile로 fmt나 clippy를 관리하는 방식이나 프로젝트 전반의 개발 흐름에 대한 이해가 생겼다. 이 구현을 끝낼 쯤 clux가 후속 이슈를 만들어줬고, PR #1838로 자연스럽게 이어졌다.
#1838 feature Predicates: add configurable cache TTL for predicate_filter
- 배경: Job, CronJob 등 자동 생성 이름을 쓰는 리소스가 많은 클러스터에서, 삭제된 리소스의 캐시 엔트리가 GC 없이 쌓이는 구조적 문제. #1836 이후 clux가 만든 후속 이슈
- 문제: predicate 캐시가 무한 증가. 자동 생성 이름의 리소스(Pod 등)가 많으면 메모리 누수
- 해결: 설정 가능한 TTL이 있는 Config 구조체 추가, polling마다 만료 엔트리 자동 제거
이슈부터 시작하기
첫 PR은 의논 없이 바로 올렸지만, PR #1838 부터는 이슈에서 먼저 설계를 의논하고 진행하기 시작했다. 바로 코드를 짜는 것보다 청사진을 먼저 그리는 편이 낫다는 걸 느꼈다. 코드베이스에 대해 이해도가 높은 사람의 의견을 들을 수 있었고, 설계 단계에서 여러 tradeoff를 고려하게 되면서 결과적으로 더 나은 방향으로 갈 수 있었다.
Aggregated Discovery
회사에서 Kubernetes API 호출을 줄이려는 생각을 하던 중, 이슈 #1813 이 눈에 들어왔다. API 리소스 정보를 가져올 때 N+2번 호출하던 것을 2번으로 줄이는 기능 요청인데, 2025년 8월에 올라온 이후 아무도 손대지 않고 있었다.
이슈에 먼저 리서치 결과를 남기고, 2단계로 나눠 PR #1873 과 PR #1876을 올렸다.
#1873 feature Implement client aggregated discovery API methods
- 배경: Kubernetes 1.27에서 beta로 도입된 Aggregated Discovery API. k8s-openapi에 타입이 없어서 직접 정의해야 했다. 2단계 중 1단계
- 문제: API 리소스 탐색 시 그룹별로 N+2번 API 호출 필요. 2025년 8월 이슈가 올라온 이후 아무도 손대지 않고 있었음
- 해결: Aggregated Discovery API 타입 정의 및 Client 메서드 추가
#1876 feature Implement aggregated discovery API methods
- 배경: v2beta1 API 응답을 기존 Discovery 내부 타입으로 변환하는 호환 레이어 설계가 핵심이었다. 2단계 중 2단계
- 문제:
Discovery::run()이 여전히 N+2번 호출하는 기존 방식만 지원 - 해결:
Discovery::run_aggregated()메서드 추가, v2 응답을 내부 타입으로 변환
clux가 느린 클러스터에서 직접 테스트한 결과:
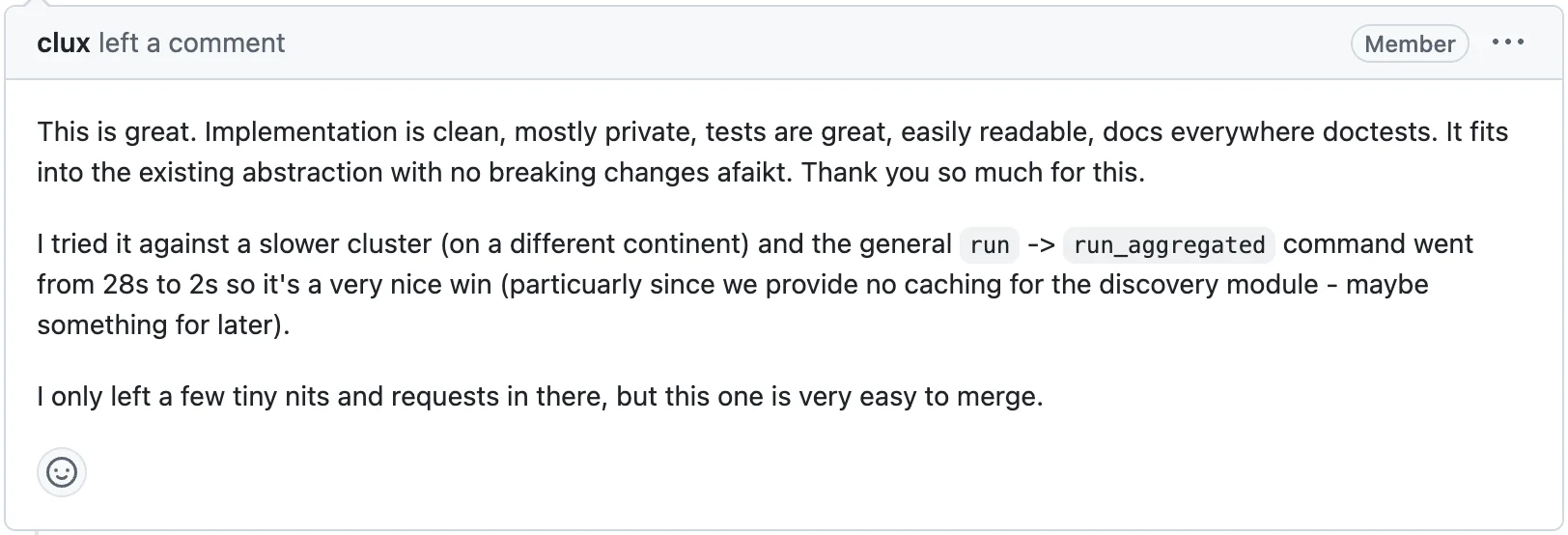
다른 대륙 클러스터에서 돌려봤는데 28초가 2초로 줄었다. 캐싱도 없이 이 정도면 꽤 좋다
그 정도로 개선될 줄은 몰랐다. 내가 짠 코드가 숫자로 차이를 만들었다는 게 신기했고, 이때 성능 벤치마킹을 체계적으로 해야겠다는 생각이 처음 들었다. 이 PR이 머지된 직후, 코멘트 하나가 달렸다.
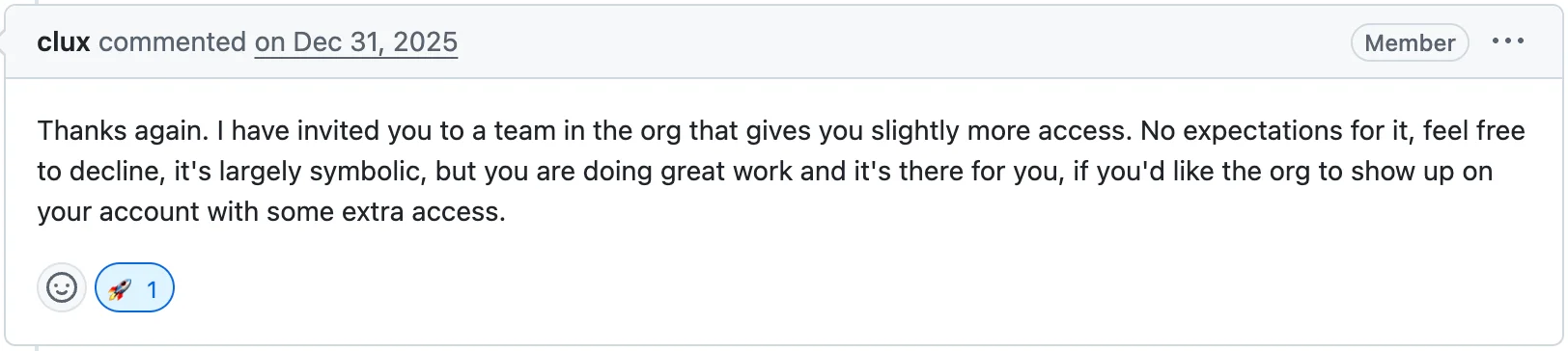
팀에 초대했다. 부담 가질 필요 없고, 상징적인 거지만 좋은 작업을 하고 있으니
예상을 전혀 못했다. 주변 사람들한테 자랑했던 것 같다. 이후로 회사에서 kube-rs에 대해 이건 뭔지, 저건 뭔지, 어떤 게 나은지 같은 질문들을 받게 됐다.
경쟁심
이슈 #1844는 다른 기여자가 root cause를 찾아냈지만 PR로 이어지지 않고 있었다. 한 달을 기다렸다가 분석을 다시 검증하고 PR #1882를 올렸다. 솔직히 경쟁심도 있었다. 제시된 설계가 좀 과한 느낌이었고, 더 단순하게 짤 수 있을 것 같았다. 기여의 동기가 꼭 고상할 필요는 없다고 생각한다. 회사 코드 개선, 호기심, 경쟁심, 어떤 것이든 동기가 다양할수록 오래 하게 되는 것 같다.
#1882 bug fix Distinguish between initial and resumed watch phases
- 배경: Kubernetes 1.27의 WatchList feature gate가 켜진 환경에서만 발생하는 문제.
sendInitialEvents파라미터의 의미가 초기 연결과 재연결에서 달라야 하는데 구분이 없었다 - 문제: streaming_lists 모드에서 ~290초마다 중복 이벤트 발생. 재연결 시
sendInitialEvents=true로 전체 리소스 재전송 - 해결:
WatchPhaseenum으로 초기 watch와 재연결 구분, 재연결 시 initial events 요청 안 함
릴리즈와 버전
PR #1884는 subresource 메서드의 API를 개선하는 breaking change였는데, 마침 3.0.0 마일스톤 타이밍에 맞아서 포함될 수 있었다.
#1884 improvement Make subresource methods more ergonomic
- 배경: client-go에서는 typed 파라미터를 받는 것이 기본인데, kube-rs의 subresource 메서드만 raw bytes를 요구하고 있었다. 이슈에서 API 일관성에 대한 논의가 있었고,
json!매크로 사용이 어려워지는 tradeoff를 clux와 조율 - 문제:
replace_status등에서serde_json::to_vec()을 직접 호출해야 하는 비일관적 API - 해결:
Vec<u8>대신&K where K: Serialize로 시그니처 변경
PR #1936은 dependabot이 올린 rand 0.10 업데이트 PR이 breaking API change를 처리하지 않아 CI가 실패한 걸 받아서 마이그레이션한 작업이다. 이후 이슈 #1938에서는 tower-http 의존성 하한값이 실제 사용 API보다 낮게 선언돼 빌드가 깨지는 문제가 보고됐다. 이런 것들을 보면서 의존성 하한값을 제대로 관리하는 게 오픈소스의 완성도에 직결된다는 걸 느꼈다.
#1936 infra Update rand dev-dependency from 0.9 to 0.10
- 배경: dependabot은 버전 범프만 하고 breaking API 변경은 처리하지 않는다. rand 0.10에서 trait 이름이 바뀐 것을 사람이 직접 마이그레이션해야 했다
- 문제: dependabot이 rand 0.10 버전만 올리고 breaking API change 미처리, CI 실패
- 해결:
rand::Rng→rand::RngExt이름 변경 적용 (dev-dependency만 해당)
오픈소스의 프로세스
이슈 #1857은 이미 관련 PR #1867이 머지되어 있었는데 열린 채로 남아 있었다. 닫아도 되는 건지 물어봤더니, 이슈가 열렸을 때는 몰랐지만 작업을 2단계로 나누는 게 맞겠다는 판단이 나왔고, 쉬운 부분이 끝난 뒤 어려운 부분에 대해 이슈 #1892가 새로 열렸다. 이슈를 닫는 것도 하나의 판단이고, 작업 범위를 나누는 것도 프로세스라는 걸 알게 됐다.
이 이슈를 기반으로 PR #1894를 작업했는데, 충분히 고민해서 구현한 결과물에 대해 clux가 tower의 ExponentialBackoff 대신 커스텀 구현을 택한 부분을 짚으면서도 "Looks good to me"라는 피드백을 줬다. 이슈를 올린 사람과 구현하는 사람 사이에서 clux가 중계하면서 코드 리뷰도 해주는 구조가 재밌었다.
#1894 feature Add RetryPolicy for client-level request retries
- 배경: tower의 미들웨어 레이어 구조를 활용해, 개별 API 호출 코드를 수정하지 않고 Client 수준에서 투명하게 재시도하도록 설계.
backon크레이트를 kube-client의 새 의존성으로 추가 - 문제:
get,list등 일반 API 호출은 일시적 오류(429/503/504)에 무방비 - 해결:
tower::retry::Policy를 구현하는RetryPolicy추가. 지수 백오프 적용
버그 사냥
이 RetryPolicy를 구현하면서 기존 watcher 코드를 읽다가 버그를 발견했다.
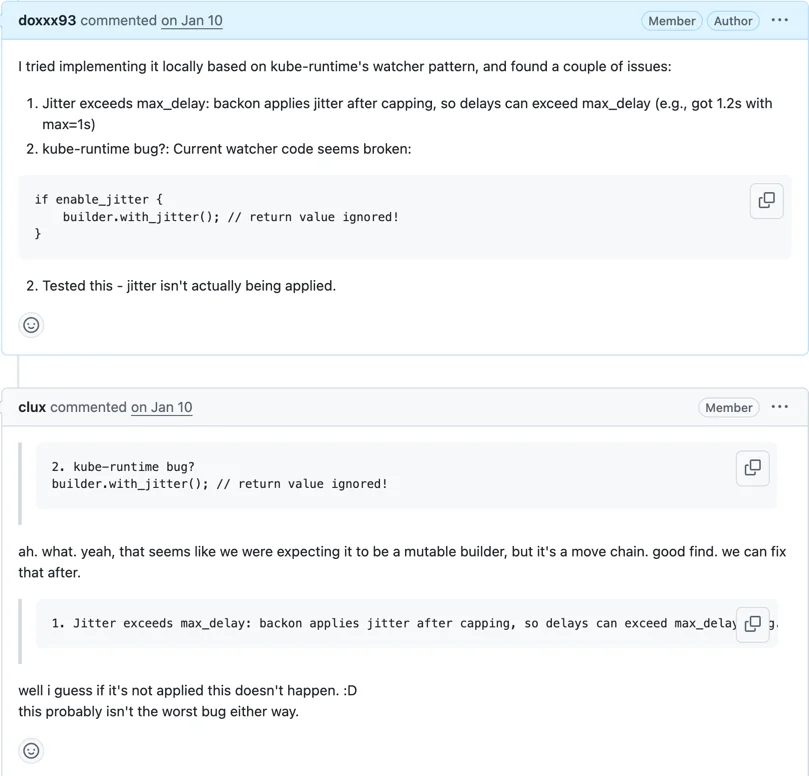
"아 뭐야. mutable builder인 줄 알았는데 move chain이었네. 좋은 발견이다"
jitter가 max_delay를 넘는 문제도 보고했는데, "애초에 jitter가 적용이 안 되고 있었으니 이 버그도 안 터진 거지 :D"
builder 패턴인데 반환값을 버리고 있어서, jitter가 켜져 있지만 실제로는 적용되지 않는 상태였다.
기능을 만들려고 주변 코드를 읽다 보니 기존 버그가 보이는 식이었다. PR #1897로 수정했다.
#1897 bug fix Fix watcher ExponentialBackoff jitter ignored
- 배경:
backon의 builder는&mut self가 아니라self를 move로 소비하는 방식. 반환값을 무시하면 컴파일은 되지만 설정이 적용되지 않는 silent bug가 된다. jitter가 없으면 재연결 시 thundering herd 위험 - 문제:
builder.with_jitter()반환값을 버려서 jitter 설정이 실제로 적용되지 않음 - 해결: 반환값을 builder에 재할당하여 jitter 정상 동작
실수
이슈 #1906에서는 의욕이 과했다. 이미 올라와 있던 PR #1907을 충분히 살피지 않고 PR #1908을 올렸다. 해당 PR의 변경 범위가 넓다고 느꼈고 더 작게 고칠 수 있다고 생각했는데, 돌이켜보면 성급했다. PR #1914에서는 로컬 동작만 확인하고 approve를 눌렀다가 다른 리뷰어가 API 설계의 근본적인 문제를 제기했다. approve는 "이 코드가 머지되어도 좋다"는 뜻인데, 확인하지 않은 부분까지 보증한 셈이 됐다.
#1908 bug fix Fix OptionalEnum transform skipping schemas with description
- 배경: kube-derive의 CRD 생성 파이프라인은 schemars 출력을 후처리하는데, optional enum 감지 로직이 스키마 객체의 키 개수(
o.len() == 1)에 의존하고 있었다. doc comment 하나만 추가해도 깨지는 취약한 조건 - 문제: optional enum 필드에 doc comment가 있으면
description이 추가되어 transform이 스킵. 잘못된 CRD 생성 - 해결:
o.len() == 1필터 제거,anyOf패턴 매칭 조건만으로 충분
CI와 인프라
기능이나 버그 수정 이후에는 대부분이 놓치거나 방치하는 프로젝트 기반 쪽에 눈이 갔다.
계기는 회사 제품의 CI를 개선하면서였다. rustfmt, clippy, cargo 설정을 정비하다 보니 kube-rs에도 같은 종류의 개선점이 보였다. resolver = "1"이 오래된 설정인데 우연히 CI가
통과하고 있던 상황을 발견하기도 했고(이슈 #1902), 코드에 남아있던 불필요한 #[allow(clippy::...)] 속성을
정리하거나(PR #1930), Docker Hub rate limit으로 flaky해지는 CI를
고치는(PR #1913) 작업들이었다. 화려하지는 않지만 workaround를 제대로 고치는 재미가 있었다.
#1913 infra Reduce CI flakiness from Docker Hub rate limits
- 배경: k3d 기반 integration test에서
busybox이미지를 매번 Docker Hub에서 pull하는 구조. anonymous pull 제한(100회/6시간)에 걸리면 테스트 전체가 실패 - 문제: Docker Hub rate limit으로
busybox이미지 pull 실패, CI 간헐적 실패 - 해결: busybox 태그를
stable로 통일, k3d에 이미지를 미리 import
#1930 infra Remove obsolete lint suppressions
- 배경: clippy는 버전이 올라가면서 false positive가 수정되지만, 그때 추가했던
#[allow]속성은 코드에 그대로 남는다.clippy::mut_mutex_lock,clippy::arc_with_non_send_sync등이 이미 불필요해진 상태였다 - 문제: clippy 업데이트로 이미 수정된 false positive에 대한
#[allow(clippy::...)]이 남아있음 - 해결: 불필요한 lint suppression 제거, 일부는 실제 경고를 수정
PR #1937은 memory benchmark CI였다. 회사 제품에서도 버전이 올라갈 때마다 성능 추적이 필요하다고 느끼고 있었는데, 여기서 초석을 다져볼 수 있었다. 이 작업을 하면서 한 가지 물어봤다.
#1937 infra Add memory benchmark CI workflow
- 배경: watcher의 리소스 수별 메모리 사용량을 JSON으로 출력하고, PR마다 이전 결과와 자동 비교하는 구조. 별도 테스트 리포지토리에서 워크플로우를 검증한 후 본 프로젝트에 적용
- 문제: 버전 업데이트 시 메모리 프로파일 회귀를 자동 감지하는 수단이 없음
- 해결: memory.rs 벤치마크의 JSON 출력 + GitHub Actions 워크플로우 추가, 150% 초과 시 PR 코멘트
다른 사람의 PR을 merge한다는 게 솔직히 겁이 있었고, 권한은 있지만 계속 미루고 있었다.
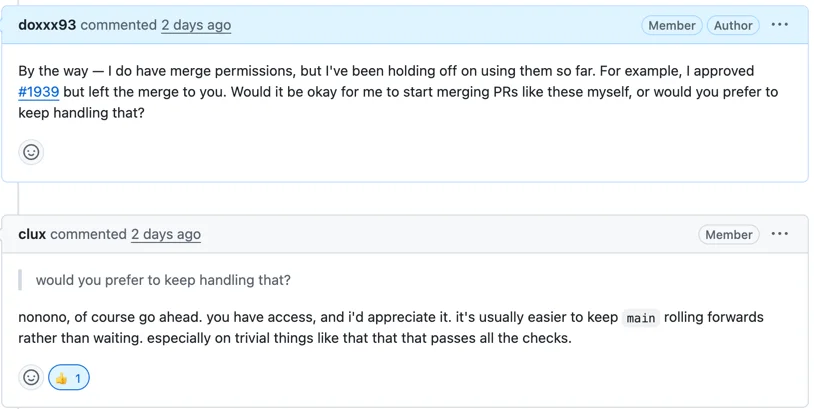
merge 권한은 있지만 지금까지 쓰지 않고 있었다. 예를 들어 #1939도 approve만 하고 merge는 남겨뒀다. 이런 PR을 직접 merge해도 괜찮을까?
당연하지, 기다리는 것보다 main을 계속 굴리는 게 낫다. 특히 이런 사소한 건
clux에게 merge는 판단의 문제가 아니라 흐름의 문제였다. CI가 통과하고 사소한 변경이면 굳이 기다릴 이유가 없다는 거다. 내가 무겁게 느끼던 걸 clux는 당연하게 보고 있었고, 그 관점을 받아들이고 나서부터는 approve된 PR을 merge하기 시작할 수 있었다.
이런 CI 작업들을 하면서, 앞서 의존성 하한값 문제에서 느꼈던 것도 다시 떠올랐다. 결국 PR #1940으로 이어졌다.
cargo -Z direct-minimal-versions
로 의존성 하한값이 실제로 컴파일되는지 검증하는 CI를 추가하는 작업인데, GitHub Actions, cargo, 의존성 관리가 복잡하게 얽혀서 가장 어려운 PR이었다.
#1940 infra Add minimal-versions CI check
- 배경:
Cargo.toml에foo = ">=1.0"이라고 써도 1.0에서 실제로 빌드되는지는 아무도 확인하지 않는다. nightly 전용-Z direct-minimal-versions플래그로 최소 버전을 resolve하되, 전이 의존성까지 최소화하는-Z minimal-versions와 달리 직접 의존성만 최소화해서 실용적인 검증이 가능 - 문제:
Cargo.toml의 의존성 하한값이 실제 컴파일 가능한지 검증 없음, 하한값 drift 발생 - 해결:
cargo +nightly update -Z minimal-versions로 최소 버전 resolution 후 빌드 검증 CI 추가
돌아보며
시작은 회사 코드를 개선하고 싶어서였고, 끝나고 보니 내가 기여한 릴리즈 버전을 회사에서 실제로 쓰게 됐다. 직접 수정한 버그 픽스가 회사 제품에서 돌아가고 있고, 반대로 회사 CI를 정비하면서 발견한 것들이 kube-rs PR로 이어지기도 했다. 둘이 완전히 분리된 게 아니라 계속 왔다 갔다 했다.
PR을 쪼개면서 작업하는 게 자연스러워졌다. 하나를 고치면 다음이 보였고, 리뷰를 받으면 배울 게 생겼다. Aggregated Discovery처럼 리서치를 먼저 이슈에 남기고 단계별로 PR을 나누는 흐름은 회사 일에서도 어떤 호흡으로 가는 게 좋은지를 배우는 데 영향을 줬다. 비동기 소통도 오픈소스라 각자 생업이 있고, 각자의 페이스대로 개발하는 게 오히려 자연스러웠다.
lint를 두 번 틀렸던 첫 PR, 다른 사람의 PR을 제대로 보지 않고 올렸던 #1908, 확인 없이 눌렀던 approve. 다 기록으로 남아 있다. 오픈소스의 breaking change를 목격하면서 semver와 API 안정성에 대해 고민하게 됐고, 코드를 쓸 때 tradeoff를 더 따지게 됐다. 몇 달 전 lint를 틀리던 사람이 이제 다른 기여자의 PR를 리뷰하는 쪽에 서 있다. 그 사이에 실수가 없었던 건 아니고, 실수를 하면서 조금씩 나아진 것 같다.
수많은 사람들이 쓰는 라이브러리에 부족한 내가 기여를 계속 해도 괜찮은 건지. merge 버튼을 누르는 게 아직 편하지 않고, 더 잘해지고 싶은데 어디까지가 내 역할인지도 아직 감을 잡는 중이다.
그래도 코드에 내 흔적이 남아가는 것, 내가 만드는 것들이 프로젝트를 지탱하는 느낌. 차근차근 해내는 게 즐거운 것 같다.
본문에서 언급하지 않은 나머지 PR
#1885 bug fix Add nullable to optional fields with x-kubernetes-int-or-string
- 배경: CRD를 schemars로 자동 생성하는 과정에서
x-kubernetes-int-or-string확장과nullable속성의 조합이 누락되고 있었다. 여러 관련 이슈와 PR의 논의를 추적해서 빈 부분을 찾음 - 문제:
Option<IntOrString>필드에nullable: true가 누락되어 server-side apply 실패 - 해결:
x-kubernetes-int-or-string속성이 있는 optional 필드에nullable: true자동 추가 — #1885
#1903 infra Update rustfmt config for Edition 2024
- 배경: justfile에서
find로.rs파일을 찾아 개별rustfmt를 호출하는 방식은examples/밖의 파일을 놓치거나, CI와 로컬에서 edition 플래그가 달라질 수 있었다 - 문제: rustfmt 호출이
find명령어와 수동--edition플래그에 의존, CI/로컬 동작 불일치 가능 - 해결:
rustfmt.toml에style_edition = "2024"추가,cargo +nightly fmt로 통일 — #1903
#1909 infra Fix typo in CI workflow comment
- CI 워크플로우 코멘트의 "comile" → "compile" 오타 수정 — #1909
#1920 bug fix Remove conflicting additionalProperties: false from schema
- 배경: Kubernetes의 structural schema 검증은
properties와additionalProperties: false가 동시에 있으면 CRD 등록을 거부한다. serde의deny_unknown_fields가 이 조합을 만들어내는데, kube-derive 스키마 후처리에서 보정이 빠져 있었다 - 문제:
#[serde(deny_unknown_fields)]가additionalProperties: false를 생성하는데, K8s가properties와 동시 존재를 거부 - 해결:
properties가 있을 때additionalProperties: false자동 제거 — #1920
#1928 improvement Use Duration::abs_diff in approx_eq test helper
- 배경: Rust 1.81에서 안정화된
Duration::abs_diff()로 수동 분기 패턴을 대체 - 문제: 테스트 헬퍼에서
if a > b { a - b } else { b - a }패턴으로 절대값 차이 계산 - 해결:
Duration::abs_diff()표준 메서드로 교체 — #1928
#1934 bug fix Fix OptionalEnum transform for complex enums
- 배경: #1908 머지 후 이슈 코멘트로 추가 실패 케이스가 보고됨. 단순 enum과 복합 enum(
oneOfvariant)의 스키마 구조 차이를 커버하지 못하고 있었다 - 문제: #1908 이후에도
oneOf를 사용하는 복합 enum은 여전히 잘못된 CRD 생성 - 해결:
first.contains_key("enum")체크 제거,anyOf구조 패턴만으로 매칭 — #1934