4 Months of Contributing to kube-rs

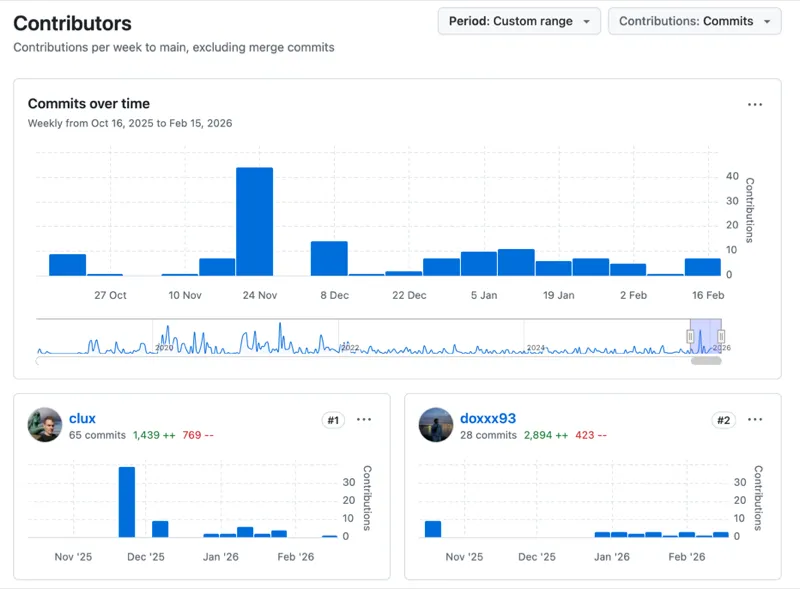
In October 2025, I read an issue on GitHub. Four months later, 20 PRs had been merged and I'd been invited as a project member.
Here's a record of what happened in between.
How It Started
We were using kube-rs at work. It's a Kubernetes client library written in Rust, but we weren't making the most of it. Our codebase relied on polling, and I thought switching to watch would be more efficient, which would also let us use reflector's store. So I decided to dig deeper into kube-rs.
While looking into the reflector and watch side of things, checking for unresolved issues or stability problems, I naturally started browsing the issue tracker.
Work Log
First contribution
Issue #1830 was a predicate filter bug. When a resource was deleted and recreated with the same name, the controller wouldn't recognize the new resource because the cache identified resources by name alone. Looking at the HashMap in the predicate cache, I had a sense of how to fix it.
I opened PR #1836. It was a single file change, so there wasn't much pressure.
#1836 bug fix fix(predicate): track resource UID to handle recreated resources
- Context: Kubernetes controller's predicate filter is key to reducing unnecessary reconciliation, but it identified resources by name only, failing to handle the recreation scenario
- Problem: When a resource is deleted and recreated with the same name, the predicate cache treats them as the same resource. The controller misses the new resource
- Fix: Introduced
PredicateCacheKeythat includes the resource UID
The first review from maintainer clux:
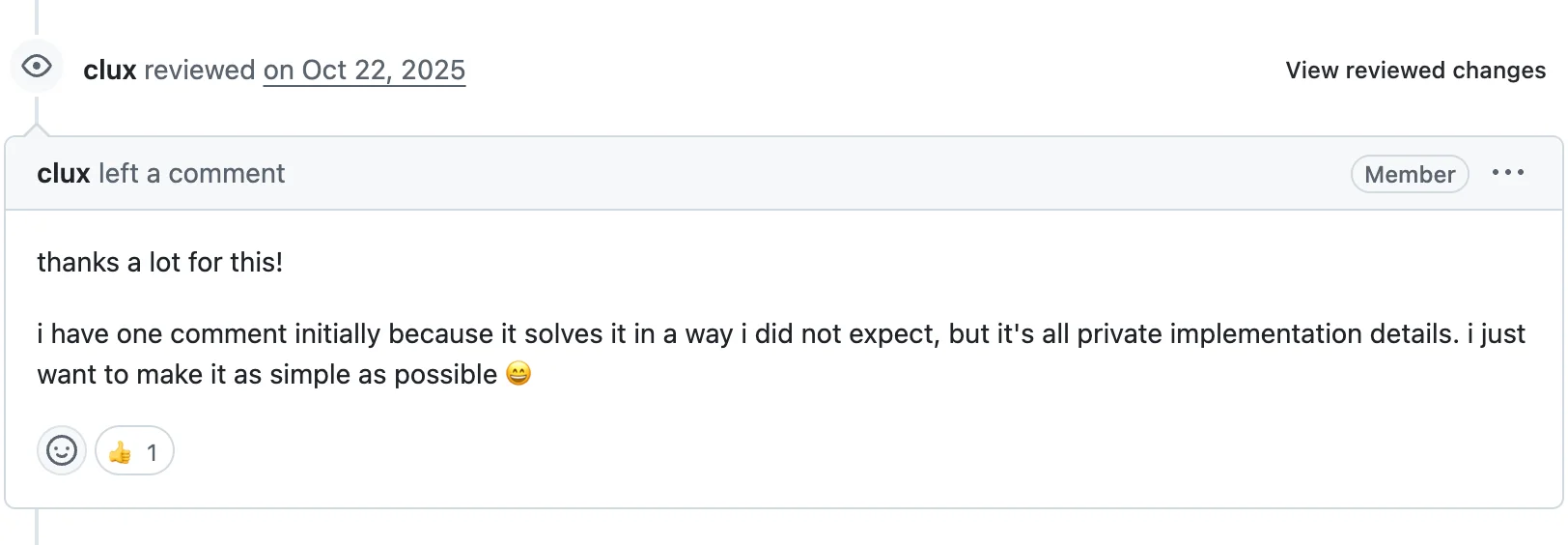

He said it solved the problem in a way he didn't expect. I revised it in the direction he suggested and the code became cleaner. I failed lint twice in a row during this process, but that's how I learned about the project's justfile for managing fmt and clippy, and the overall development workflow. As I was wrapping up, clux created a follow-up issue, which naturally led to PR #1838.
#1838 feature Predicates: add configurable cache TTL for predicate_filter
- Context: In clusters with many auto-generated resource names (Jobs, CronJobs, etc.), cache entries for deleted resources accumulate without GC. Follow-up issue created by clux after #1836
- Problem: Predicate cache grows unbounded. With many auto-named resources (Pods, etc.), this becomes a memory leak
- Fix: Added Config struct with configurable TTL, expired entries automatically removed on each poll
Starting with issues
I'd submitted my first PR without any prior discussion, but starting from PR #1838, I began discussing designs in issues first. Sketching a blueprint before writing code turned out to be better. I could get input from someone with deep knowledge of the codebase, and considering tradeoffs at the design stage led to better outcomes.
Aggregated Discovery
While thinking about reducing Kubernetes API calls at work, issue #1813 caught my eye. It was a feature request to reduce API resource discovery from N+2 calls to just 2, filed in August 2025 with no one picking it up.
I posted my research in the issue first, then split the work into two stages: PR #1873 and PR #1876.
#1873 feature Implement client aggregated discovery API methods
- Context: Aggregated Discovery API, introduced as beta in Kubernetes 1.27. Types weren't in k8s-openapi, so they had to be defined from scratch. Stage 1 of 2
- Problem: API resource discovery required N+2 calls per group. The issue had been open since August 2025 with no one picking it up
- Fix: Defined Aggregated Discovery API types and added Client methods
#1876 feature Implement aggregated discovery API methods
- Context: The core challenge was designing a compatibility layer to convert v2beta1 API responses into the existing Discovery internal types. Stage 2 of 2
- Problem:
Discovery::run()only supported the legacy N+2-call approach - Fix: Added
Discovery::run_aggregated()method, converting v2 responses to internal types
clux tested it against a slower cluster:
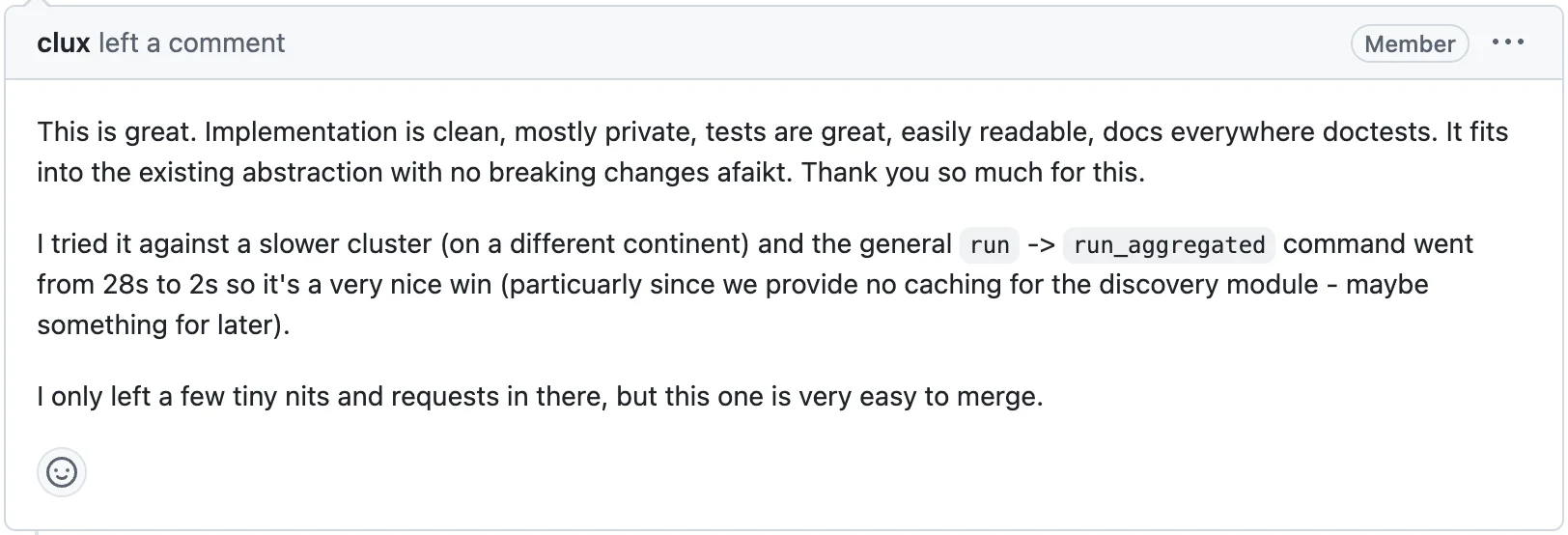
I didn't expect that much improvement. It was fascinating to see code I wrote make a measurable difference, and this was when I first thought about doing systematic performance benchmarking. Right after this PR was merged, a comment appeared.
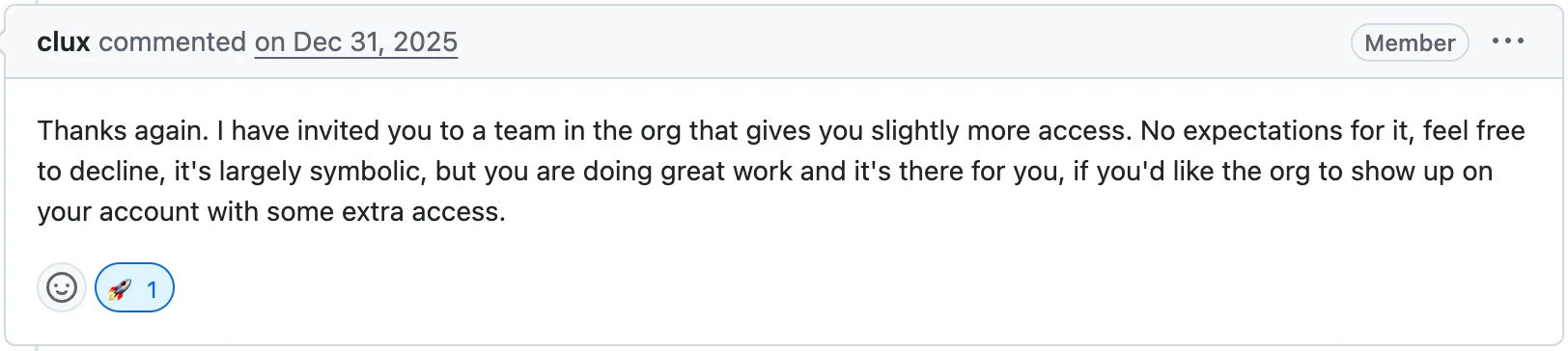
I didn't see it coming at all. I think I went around telling everyone. After that, people at work started asking me about kube-rs, things like what this or that feature does, or which approach is better.
Competitiveness
Issue #1844 had its root cause identified by another contributor, but no PR followed. I waited a month, re-verified the analysis, and opened PR #1882. Honestly, there was some competitiveness involved. The proposed design felt excessive, and I thought I could write something simpler. I don't think the motivation for contributing needs to be noble. Improving work code, curiosity, competitiveness, whatever it is, the more diverse the motivation, the longer you keep at it.
#1882 bug fix Distinguish between initial and resumed watch phases
- Context: Only occurs in environments with Kubernetes 1.27's WatchList feature gate enabled. The
sendInitialEventsparameter should have different semantics for initial connection vs reconnection, but there was no distinction - Problem: Duplicate events every ~290 seconds in streaming_lists mode. On reconnection,
sendInitialEvents=truecaused full resource retransmission - Fix:
WatchPhaseenum to distinguish initial watch from reconnection; skip initial events on reconnection
Releases and versioning
PR #1884 was a breaking change to make subresource methods more ergonomic. The timing worked out to land it in the 3.0.0 milestone.
#1884 improvement Make subresource methods more ergonomic
- Context: In client-go, typed parameters are the default, but kube-rs subresource methods required raw bytes. The issue had discussion about API consistency, and the tradeoff of making
json!macro usage harder was coordinated with clux - Problem:
replace_statusand similar methods required manualserde_json::to_vec()calls — inconsistent API - Fix: Changed signatures from
Vec<u8>to&K where K: Serialize
PR #1936 picked up a dependabot-initiated rand 0.10 update that had failed CI due to unhandled breaking API changes, and I completed the migration. Then issue #1938 reported that tower-http's declared lower bound was below the API version actually used, breaking builds. Seeing these issues made me realize that properly managing dependency lower bounds is directly tied to the quality of an open source project.
#1936 infra Update rand dev-dependency from 0.9 to 0.10
- Context: Dependabot only bumps versions without handling breaking API changes. The trait rename in rand 0.10 had to be manually migrated
- Problem: Dependabot bumped rand to 0.10 without handling breaking API changes, CI failed
- Fix: Applied
rand::Rng→rand::RngExtrename (dev-dependency only)
Open source process
Issue #1857 had a related PR #1867 already merged but the issue was still open. When I asked if it could be closed, the judgment was that the work should be split into two stages, something that wasn't apparent when the issue was first filed. After the easy part was done, issue #1892 was opened for the harder part. I learned that closing an issue is itself a judgment call, and scoping work is part of the process.
I worked on PR #1894 based on this issue. clux pointed out my choice of a custom implementation over tower's ExponentialBackoff, but still gave a "Looks good to me." The dynamic was interesting: clux mediating between the issue reporter and the implementer while doing code review.
#1894 feature Add RetryPolicy for client-level request retries
- Context: Designed to leverage tower's middleware layer architecture for transparent retries at the Client level, without modifying individual API call sites. Added
backoncrate as a new kube-client dependency - Problem:
get,list, and other one-shot API calls were defenseless against transient errors (429/503/504) - Fix: Added
RetryPolicyimplementingtower::retry::Policywith exponential backoff
Bug hunting
While implementing RetryPolicy, I was reading the existing watcher code and found a bug.
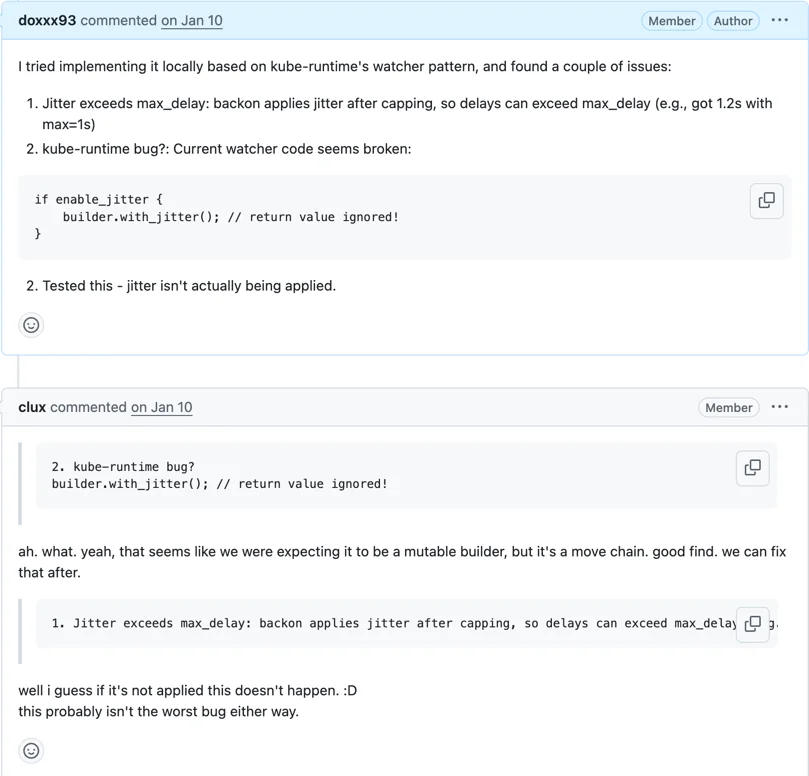
A builder pattern where the return value was being discarded. Jitter was enabled in name but never actually applied.
Bugs in existing code surfaced while reading surrounding code to build a new feature. Fixed in PR #1897.
#1897 bug fix Fix watcher ExponentialBackoff jitter ignored
- Context:
backon's builder consumesselfby move rather than&mut self. Ignoring the return value compiles fine but silently drops the configuration. Without jitter, reconnections risk thundering herd - Problem:
builder.with_jitter()return value was discarded, so the jitter setting was never actually applied - Fix: Reassign the return value to the builder so jitter works correctly
Mistakes
I got too eager with issue #1906. I opened PR #1908 without properly reviewing the existing PR #1907. I thought the scope of that PR was too broad and I could fix it more narrowly, but in retrospect, I was hasty. With PR #1914, I hit approve after only testing locally, and another reviewer raised a fundamental issue with the API design. An approve means "this code is good to merge," but I'd vouched for parts I hadn't verified.
#1908 bug fix Fix OptionalEnum transform skipping schemas with description
- Context: kube-derive's CRD generation pipeline post-processes schemars output, but the optional enum detection logic depended on schema object key count (
o.len() == 1). A fragile condition that broke with just one doc comment added - Problem: Optional enum fields with doc comments gained a
descriptionfield, causing the transform to skip. Incorrect CRD generated - Fix: Removed
o.len() == 1filter;anyOfpattern matching alone is sufficient
CI and infrastructure
After features and bug fixes, my attention shifted to the project's foundation, the kind of things most people overlook or leave untouched.
The trigger was improving CI at work. While sorting out rustfmt, clippy, and cargo configs, I noticed the same kinds of improvements needed in kube-rs. I found that resolver = "1" was an outdated setting that happened to pass CI by coincidence (issue #1902), cleaned up obsolete #[allow(clippy::...)] attributes (PR #1930), and fixed flaky CI caused by Docker Hub rate limits (PR #1913). Not glamorous, but there was a certain satisfaction in properly fixing workarounds.
#1913 infra Reduce CI flakiness from Docker Hub rate limits
- Context: k3d-based integration tests pulled the
busyboximage from Docker Hub on every run. Hitting the anonymous pull limit (100 pulls/6 hours) would fail the entire test suite - Problem: Docker Hub rate limits caused
busyboximage pull failures, intermittent CI failures - Fix: Unified busybox tag to
stable, pre-imported image into k3d
#1930 infra Remove obsolete lint suppressions
- Context: As clippy updates fix false positives, the
#[allow]attributes added for them remain in the code.clippy::mut_mutex_lock,clippy::arc_with_non_send_sync, and others had become unnecessary - Problem:
#[allow(clippy::...)]attributes remained for false positives already fixed in newer clippy versions - Fix: Removed unnecessary lint suppressions; fixed some actual warnings
PR #1937 was a memory benchmark CI workflow. I'd been feeling the need for performance tracking across releases at work too, and this was a chance to lay that groundwork. While working on this, I asked something that had been on my mind.
#1937 infra Add memory benchmark CI workflow
- Context: Outputs watcher memory usage per resource count as JSON, automatically comparing against previous results per PR. Validated the workflow in a separate test repository before applying to the main project
- Problem: No automated way to detect memory profile regressions across version updates
- Fix: Added memory.rs benchmark JSON output + GitHub Actions workflow, PR comment when exceeding 150%
I'd honestly been afraid of merging other people's PRs. I had the permissions but kept putting it off.
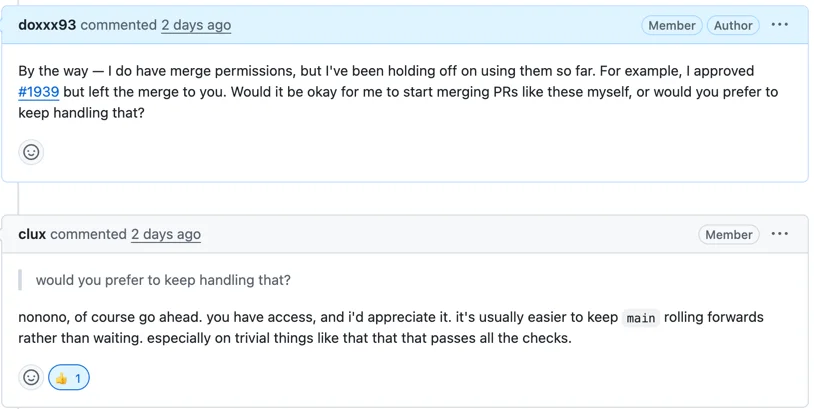
For clux, merging wasn't a matter of judgment but of flow. If CI passes and the change is trivial, there's no reason to wait. What I was treating as weighty, clux saw as obvious. Once I accepted that perspective, I started merging approved PRs.
Working on these CI tasks also brought back the concerns from the dependency lower bound issues. That eventually led to PR #1940. Adding CI to verify that dependency lower bounds actually compile using cargo -Z direct-minimal-versions. GitHub Actions, cargo, and dependency management were deeply intertwined, making it the hardest PR I've worked on.
#1940 infra Add minimal-versions CI check
- Context: Writing
foo = ">=1.0"inCargo.tomldoesn't mean it actually builds with 1.0. The nightly-only-Z direct-minimal-versionsflag resolves to minimum versions, but unlike-Z minimal-versions, it only minimizes direct dependencies, making verification practical - Problem: No verification that dependency lower bounds in
Cargo.tomlactually compile; lower bound drift - Fix: Added CI that resolves minimum versions via
cargo +nightly update -Z minimal-versionsthen verifies the build
Looking Back
It started because I wanted to improve our codebase at work, and by the end, we were running a release version that included my contributions. Bug fixes I'd made were running in our product, and conversely, things I found while fixing our CI turned into kube-rs PRs. The two weren't separate; they kept feeding into each other.
Splitting work into smaller PRs became natural. Fix one thing and the next thing comes into view. Get a review and there's something new to learn. The rhythm of posting research in an issue first and splitting PRs into stages, like with Aggregated Discovery, influenced how I approach work at the company too. Async communication felt natural as well. Everyone has their own schedule in open source, and working at your own pace was just how things worked.
The first PR where I failed lint twice, #1908 where I didn't look at an existing PR, the approve I clicked without proper review. It's all on record. Witnessing breaking changes in open source made me think about semver and API stability, and I started weighing tradeoffs more carefully when writing code. The person who was failing lint a few months ago is now on the reviewing side for other contributors' PRs. Not that I stopped making mistakes, but I think I got a little better by making them.
Is it really okay for someone as lacking as me to keep contributing to a library used by so many people? Pressing the merge button still isn't comfortable, and I want to get better, but I'm still figuring out where my role ends.
Still, watching my traces accumulate in the code, feeling like what I build helps sustain the project. Steadily getting things done has been enjoyable.
Remaining PRs not covered above
#1885 bug fix Add nullable to optional fields with x-kubernetes-int-or-string
- Context: In the CRD auto-generation pipeline via schemars, the combination of
x-kubernetes-int-or-stringextension andnullableattribute was being dropped. Found the gap by tracing discussions across multiple related issues and PRs - Problem:
Option<IntOrString>fields missingnullable: true, causing server-side apply failures - Fix: Automatically add
nullable: trueto optional fields withx-kubernetes-int-or-string— #1885
#1903 infra Update rustfmt config for Edition 2024
- Context: The justfile was using
findto locate.rsfiles and callingrustfmtindividually, which could miss files outsideexamples/or cause edition flag mismatches between CI and local - Problem: rustfmt invocation depended on
findcommand and manual--editionflag, risking CI/local inconsistency - Fix: Added
style_edition = "2024"torustfmt.toml, unified tocargo +nightly fmt— #1903
#1909 infra Fix typo in CI workflow comment
- "comile" → "compile" typo fix in CI workflow comment — #1909
#1920 bug fix Remove conflicting additionalProperties: false from schema
- Context: Kubernetes structural schema validation rejects CRD registration when
propertiesandadditionalProperties: falsecoexist. serde'sdeny_unknown_fieldsproduces this combination, but kube-derive's schema post-processing wasn't correcting it - Problem:
#[serde(deny_unknown_fields)]generatedadditionalProperties: false, which K8s rejects whenpropertiesis present - Fix: Automatically remove
additionalProperties: falsewhenpropertiesexists — #1920
#1928 improvement Use Duration::abs_diff in approx_eq test helper
- Context: Replacing manual branching pattern with
Duration::abs_diff()stabilized in Rust 1.81 - Problem: Test helper computed absolute difference with
if a > b { a - b } else { b - a }pattern - Fix: Replaced with
Duration::abs_diff()standard method — #1928
#1934 bug fix Fix OptionalEnum transform for complex enums
- Context: After #1908 merged, additional failure cases were reported in issue comments. The schema structure difference between simple enums and complex enums (
oneOfvariants) wasn't covered - Problem: Complex enums using
oneOfstill generated incorrect CRDs even after #1908 - Fix: Removed
first.contains_key("enum")check;anyOfstructural pattern matching alone is sufficient — #1934